Meet  The assurance layer for AI Coding era.
The assurance layer for AI Coding era.
Autter reviews code, tests product impact, checks security, governs releases, and closes the loop from production failure to verified fix.
One hire, every task.
The entire assurance layer, hired in one click
Test execution, regression checks, security review, release sign-off. Every duty of the assurance layer, handled on every pull request before merge, not after deploy.
Everything in one workspace
Repos, PRs, docs, issues, Sentry, PostHog, Grafana, CI, and deployments flow into Autter, which maps code, APIs, schema, routes, owners, hotspots, and blast radius into product memory.
Explore IntegrationsFrom the codebase, PRs, and your existing guidelines, Autter generates documentation, changelogs, and release notes, and keeps every page current on each merge.
Explore Pipeline AutomationSignup, checkout, uploads, and webhooks become end-to-end missions, probed with malformed inputs and boundary cases. Unit, API, and integration tests fill the coverage gaps, and flaky tests get re-forged.
Explore Pipeline AutomationEvery pull request executes in an isolated sandbox against your base branch. Dependencies are vetted against real registries, secrets and CVEs are caught at the gate, and every change is classified human or AI.
Explore Code ReviewEvery production error is pinned to the code that caused it, with the why, the where, and the owner. Confirmed failures become fix PRs, re-run in the sandbox and verified before they ship.
Explore AnalyticsQuality trends, hotspots, flaky rate, cycle time, and coverage roll into one release-readiness verdict. Every repo, every PR, every release. Your assurance layer never clocks out.
Explore Analytics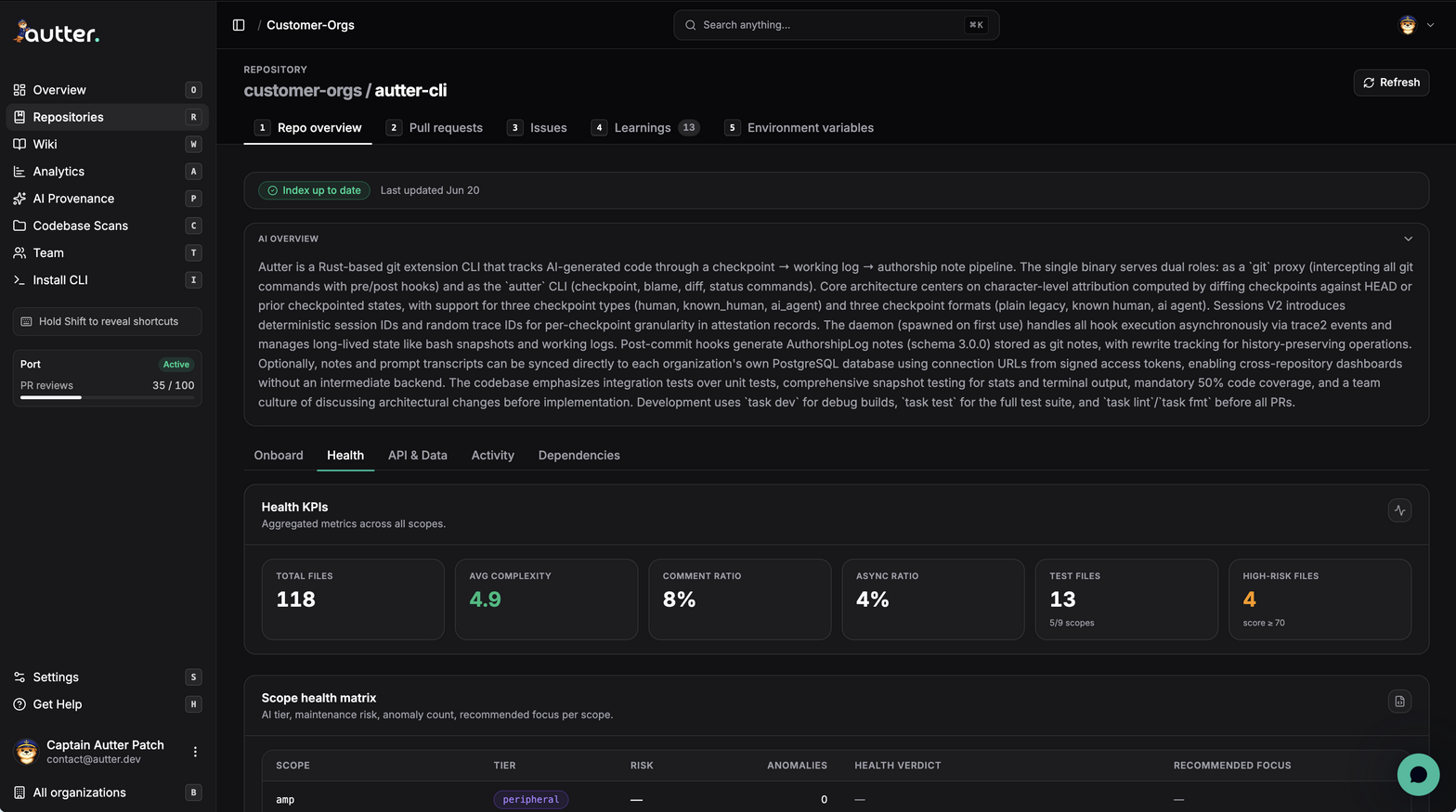
Autter executes every human and AI change across every pull request—so clean code merges with confidence and risky code never ships.
How Autter works / Step 1
Connect every signal.
Repos, pull requests, docs, issue trackers, error trackers, analytics, CI, and deployments flow into Autter.
How Autter works / Step 2
Build product memory.
Autter maps code, APIs, database schema, frontend routes, tests, docs, owners, hotspots, and blast radius.
How Autter works / Step 3
Write the docs.
From the codebase, PRs, and your existing guidelines, Autter generates documentation, changelogs, and release notes, and keeps every page current on each merge.
How Autter works / Step 4
Map the missions.
Signup, checkout, uploads, and webhooks become end-to-end missions, probed at the edges with malformed inputs, boundary cases, and visual checks across browsers and devices.
How Autter works / Step 5
Generate the tests.
From the code graph and each mission, Autter writes unit, API, and integration tests, finds coverage gaps, and detects and re-forges flaky tests.
How Autter works / Step 6
Run it in the sandbox.
Every pull request executes in an isolated sandbox. The full suite runs against your base branch, so the verdict comes from real behavior, not lint.
How Autter works / Step 7
Open every crate.
Every dependency is vetted against real registries. Phantom packages, leaked secrets, removed auth, and known CVEs are flagged at the gate and never ship.
How Autter works / Step 8
Classify human vs AI.
Every change on every pull request is classified as human-written or AI-generated, so generated code gets the extra scrutiny it deserves.
How Autter works / Step 9
Trace every error.
Sentry, PostHog, Grafana, logs, and telemetry stream into Autter. Every production error is pinned to the exact section of code that caused it, with the why, the where, and the owner.
How Autter works / Step 10
Raise the fix.
Confirmed failures become fix PRs with the root cause attached. Autter re-runs the failing case in the sandbox and verifies the patch before it ships.
How Autter works / Step 11
Measure the team.
Developer analytics roll every run's quality trends, hotspots, flaky rate, cycle time, and coverage into one release-readiness verdict.
How Autter works / Step 12
Always watching.
Every repo. Every PR. Every release. Autter learns from every finding, every fix, and every incident. Your assurance layer never clocks out.
Built for teams that ship
Autter works seamlessly with the tools and workflows you already use
Where impact is made
Teams using Autter deliver higher-quality code through focused changes and accelerated review workflows.
Seamlessly integrated with GitHub
Native GitHub integration keeps your entire team aligned and in sync at every step.
Powered by Git at its core
Autter works alongside your existing git commands, shortcuts, and development practices.
Your code never leaves the sandbox.
Autter clones, runs, and verifies inside an isolated sandbox. Only the verdict comes back out.
- Ephemeral by design
- Every pull request runs in an isolated sandbox that is destroyed the moment the verdict lands. Nothing lingers between runs.
- Never trained on
- Your source is never used to train models. It exists inside the run, and then it is gone.
- Least privilege
- Scoped, revocable tokens. Autter reads what it reviews and nothing more.
- Encrypted throughout
- In transit and at rest, from the moment the sandbox clones to the moment the verdict posts.
Fair questions, straight answers.
The things engineering leads ask us before they hand Autter a repository.
Something else on your mind? hello@autter.dev
How is Autter different from AI review bots and linters?
Review bots read the diff and leave comments. Autter executes the change: every pull request is cloned into an isolated sandbox, the suite runs against the base branch, dependencies are vetted against real registries, and the merge stays blocked until the checklist clears. The verdict comes from behavior, not pattern matching.
Does Autter replace my CI?
No. CI runs the jobs you wrote. Autter sits on top of it as the merge gate: it reads your CI signals, writes and runs the tests you are missing, and decides whether the change is safe to merge. Your pipeline stays exactly as it is.
Will this replace our human reviewers?
No. Autter clears the repetitive, easy to miss issues so your reviewers spend their time on architecture and design decisions, not on catching a missing null check.
Which languages and stacks does it support?
If your project can build and run in a container, Autter can execute it. The GitHub integration is native, and the product memory maps your code, APIs, schema, routes, and tests regardless of stack.
Do you train on our code?
No. Your source is cloned into an ephemeral sandbox for the duration of the review and torn down after. Nothing you send us is used to train models, and nothing persists beyond the run.
How is proprietary code handled?
Every review runs in an isolated sandbox built fresh for that run. Your source is not retained once the review completes, and everything in transit and at rest is encrypted.
Is there a plan for open source projects?
Yes. Public repositories run on Autter for free, with the same sandboxed execution and merge gate as a paid plan. Connect the repo and reviews start on the next pull request.
What does Autter actually flag?
Bugs the diff did not reveal, security issues, performance regressions, and logic errors, all verified by running your code rather than pattern matching it. It also calls out style and maintainability issues the way a senior reviewer would.
Can we tune what it checks for?
Yes. Point Autter at your team's standards, exclude file patterns, and weight it toward the parts of the codebase that matter most, all through a config file you own.
How long before a review lands?
Most runs finish within seconds of the pull request opening. Autter executes alongside your CI pipeline instead of after it, so the merge gate never adds to your wait.
What happens when Autter is wrong?
Every finding ships with its receipt: the exact sandbox run, the failing case, and the trace that produced it. If a finding does not hold up, you dismiss it and Autter learns from the override. Nothing blocks your merge on a hunch.
How long does onboarding take?
Install the GitHub App and pick your repos. Autter builds its product memory from the codebase on the first pass and starts reviewing the next pull request. There is no pipeline to rewrite and no config file to maintain.
How do I get access, and what does it cost?
Autter is onboarding teams from the waitlist right now. Book a demo and we will stand it up on your repositories together, then work out pricing that fits your team.